728x90
https://school.programmers.co.kr/learn/courses/30/lessons/42893
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
문제 설명
프렌즈 대학교 조교였던 제이지는 허드렛일만 시키는 네오 학과장님의 마수에서 벗어나, 카카오에 입사하게 되었다.
평소에 관심 있어하던 검색에 마침 결원이 발생하여, 검색개발팀에 편입될 수 있었고, 대망의 첫 프로젝트를 맡게 되었다.
그 프로젝트는 검색어에 가장 잘 맞는 웹페이지를 보여주기 위해 아래와 같은 규칙으로 검색어에 대한 웹페이지의 매칭점수를 계산하는 것이었다.
- 한 웹페이지에 대해서 기본점수, 외부 링크 수, 링크점수, 그리고 매칭점수를 구할 수 있다.
- 한 웹페이지의 기본점수는 해당 웹페이지의 텍스트 중, 검색어가 등장하는 횟수이다. (대소문자 무시)
- 한 웹페이지의 외부 링크 수는 해당 웹페이지에서 다른 외부 페이지로 연결된 링크의 개수이다.
- 한 웹페이지의 링크점수는 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합이다.
- 한 웹페이지의 매칭점수는 기본점수와 링크점수의 합으로 계산한다.
예를 들어, 다음과 같이 A, B, C 세 개의 웹페이지가 있고, 검색어가 hi라고 하자.
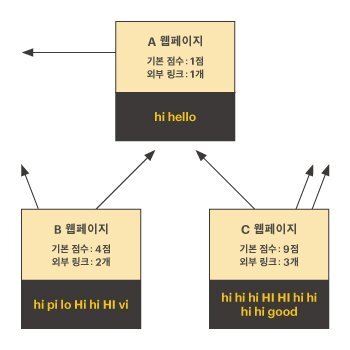
이때 A 웹페이지의 매칭점수는 다음과 같이 계산할 수 있다.
- 기본 점수는 각 웹페이지에서 hi가 등장한 횟수이다.
- A,B,C 웹페이지의 기본점수는 각각 1점, 4점, 9점이다.
- 외부 링크수는 다른 웹페이지로 링크가 걸린 개수이다.
- A,B,C 웹페이지의 외부 링크 수는 각각 1점, 2점, 3점이다.
- A 웹페이지로 링크가 걸린 페이지는 B와 C가 있다.
- A 웹페이지의 링크점수는 B의 링크점수 2점(4 ÷ 2)과 C의 링크점수 3점(9 ÷ 3)을 더한 5점이 된다.
- 그러므로, A 웹페이지의 매칭점수는 기본점수 1점 + 링크점수 5점 = 6점이 된다.
검색어 word와 웹페이지의 HTML 목록인 pages가 주어졌을 때, 매칭점수가 가장 높은 웹페이지의 index를 구하라. 만약 그런 웹페이지가 여러 개라면 그중 번호가 가장 작은 것을 구하라.
문제 유형이 풀면서 재미있었고 풀이도 어렵진 않은 편이지만, 정말 사소한 것 하나라도 틀리면 오답이 떠서 힘들었던 문제이다. 정규 표현식을 사용한 풀이도 많지만, 정규 표현식을 잘 몰라서 문자열을 다루어 풀이했다.
- head 범위를 구하고, 그 안에서 웹페이지의 이름 찾기
- body 범위를 구하고, 그 안에서 외부 링크가 발견된다면 체크하기
- body 내 텍스트에서 word가 발견된다면 체크하기
- 기본 점수와 외부 링크들의 정보를 통해 링크점수를 계산하기
- 기본 점수와 링크 점수를 합하여 매칭 점수를 구하고, 매칭 점수가 가장 높은 웹 페이지의 index를 반환하기
from collections import defaultdict
def search_word(text, word):
cnt = 0
tmp = ''
for c in text:
if c.isalpha():
tmp += c
else:
if tmp == word:
cnt += 1
tmp = ''
if tmp == word:
cnt += 1
return cnt
def solution(word, pages):
answer = 0
word = word.lower()
basic_scores = dict()
external_links = defaultdict(list)
matching_scores = dict()
page_idxs = dict()
for i, page in enumerate(pages):
html = page.split('\n')
head = html[html.index('<head>')+1:html.index('</head> ')]
body = html[html.index('<body>')+1:html.index('</body>')]
for line in head:
if '<meta property="og:url"' in line:
url = line[line.index('https://'):line.index('"/>')]
basic_scores[url] = 0
matching_scores[url] = 0
page_idxs[url] = i
break
for line in body:
line = line.lower()
while '<a href="' in line:
prev = line[:line.index('<a href="')]
basic_scores[url] += search_word(prev, word)
line = line[line.index('<a href="')+9:]
link = line[:line.index('"')]
external_links[url].append(link)
line = line[line.index('">')+2:]
basic_scores[url] += search_word(line, word)
for myLink, links in external_links.items():
for link in links:
if link in matching_scores:
matching_scores[link] += basic_scores[myLink] / len(links)
max_matching_score = -1
for myLink, basic_score in basic_scores.items():
matching_scores[myLink] += basic_score
if matching_scores[myLink] > max_matching_score:
max_matching_score = matching_scores[myLink]
answer = page_idxs[myLink]
return answer- body 부분의 한 줄에 외부 링크가 2개 이상 있을 수 있다. => while '<a href="' in line: 의 while문으로 해결
- word는 해당 웹페이지의 텍스트 내에 있다 => 외부 링크가 있다면, 태그 내부를 제외한 앞뒤 부분이 텍스트이다
728x90
'코딩테스트 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스 Level2] 시소 짝꿍 - 파이썬(Python) - 연습문제 (0) | 2023.01.31 |
|---|---|
| [프로그래머스 Level3] 길 찾기 게임 - 파이썬(Python) - 2019 KAKAO BLIND RECRUITMENT (0) | 2023.01.17 |
| [프로그래머스 Level3] 양과 늑대 - 파이썬(Python) - 2022 KAKAO BLIND RECRUITMENT (0) | 2023.01.12 |
| [프로그래머스 Level3] N으로 표현 - 파이썬(Python) (0) | 2023.01.12 |
| [프로그래머스 Level3] 공 이동 시뮬레이션 - 파이썬(Python) - 월간 코드 챌린지 시즌3 (1) | 2023.01.11 |